trident.light_ray.LightRay
- class trident.light_ray.LightRay(parameter_filename, simulation_type=None, near_redshift=None, far_redshift=None, use_minimum_datasets=True, max_box_fraction=1.0, deltaz_min=0.0, minimum_coherent_box_fraction=0.0, time_data=True, redshift_data=True, find_outputs=False, load_kwargs=None)[source]
A 1D object representing the path of a light ray passing through a simulation. LightRays can be either simple, where they pass through a single dataset, or compound, where they pass through consecutive datasets from the same cosmological simulation. One can sample any of the fields intersected by the LightRay object as it passed through the dataset(s).
For compound rays, the LightRay stacks together multiple datasets in a time series in order to approximate a LightRay’s path through a volume and redshift interval larger than a single simulation data output. The outcome is something akin to a synthetic QSO line of sight.
Once the LightRay object is set up, use LightRay.make_light_ray to begin making rays. Different randomizations can be created with a single object by providing different random seeds to make_light_ray.
Parameters
- Parameter_filename:
string or
DatasetFor simple rays, one may pass either a loaded dataset object or the filename of a dataset. For compound rays, one must pass the filename of the simulation parameter file.
- Simulation_type:
optional, string
This refers to the simulation frontend type. Do not use for simple rays. Default: None
- Near_redshift:
optional, float
The near (lowest) redshift for a light ray containing multiple datasets. Do not use for simple rays. Default: None
- Far_redshift:
optional, float
The far (highest) redshift for a light ray containing multiple datasets. Do not use for simple rays. Default: None
- Use_minimum_datasets:
optional, bool
If True, the minimum number of datasets is used to connect the initial and final redshift. If false, the light ray solution will contain as many entries as possible within the redshift interval. Do not use for simple rays. Default: True.
- Max_box_fraction:
optional, float
In terms of the size of the domain, the maximum length a light ray segment can be in order to span the redshift interval from one dataset to another. If using a zoom-in simulation, this parameter can be set to the length of the high resolution region so as to limit ray segments to that size. If the high resolution region is not cubical, the smallest side should be used. Default: 1.0 (the size of the box)
- Deltaz_min:
optional, float
Specifies the minimum
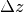 between consecutive
datasets in the returned list. Do not use for simple rays.
Default: 0.0.
between consecutive
datasets in the returned list. Do not use for simple rays.
Default: 0.0.- Minimum_coherent_box_fraction:
optional, float
Use to specify the minimum length of a ray, in terms of the size of the domain, before the trajectory is re-randomized. Set to 0 to have ray trajectory randomized for every dataset. Set to np.inf (infinity) to use a single trajectory for the entire ray. Default: 0.
- Time_data:
optional, bool
Whether or not to include time outputs when gathering datasets for time series. Do not use for simple rays. Default: True.
- Redshift_data:
optional, bool
Whether or not to include redshift outputs when gathering datasets for time series. Do not use for simple rays. Default: True.
- Find_outputs:
optional, bool
Whether or not to search for datasets in the current directory. Do not use for simple rays. Default: False.
- Load_kwargs:
optional, dict
If you are passing a filename of a dataset to LightRay rather than an already loaded dataset, then you can optionally provide this dictionary as keywords when the dataset is loaded by yt with the “load” function. Necessary for use with certain frontends. E.g. Tipsy using “bounding_box” Gadget using “unit_base”, etc. Default : None
Methods
Create list of datasets capable of spanning a redshift interval. |
|
Actually generate the LightRay by traversing the desired dataset. |
|
Create imaginary list of redshift outputs to maximally span a redshift interval. |